The documentation suggests that the sklearn OneHotEncoder should be a viable transformation when using the MimicExplainer, but I'm getting errors if I use it and set the min_frequency parameter to remove category levels with low counts.
If I set up my data preprocessor like this

(where I have ~7 categorical features, each with many levels)
# Define categorical transformer
categorical_transformer = Pipeline(
steps=[
("cat_impute", SimpleImputer(strategy="constant", fill_value='missing')),
("onehot", OneHotEncoder(drop=None, handle_unknown="infrequent_if_exist", sparse=False, min_frequency=0.01)),
]
)
# Define numeric transformer
numeric_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler()),
]
)
data_preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, numeric_features),
("cat", categorical_transformer, categorical_features)
],
remainder="drop",
)
I get the following error
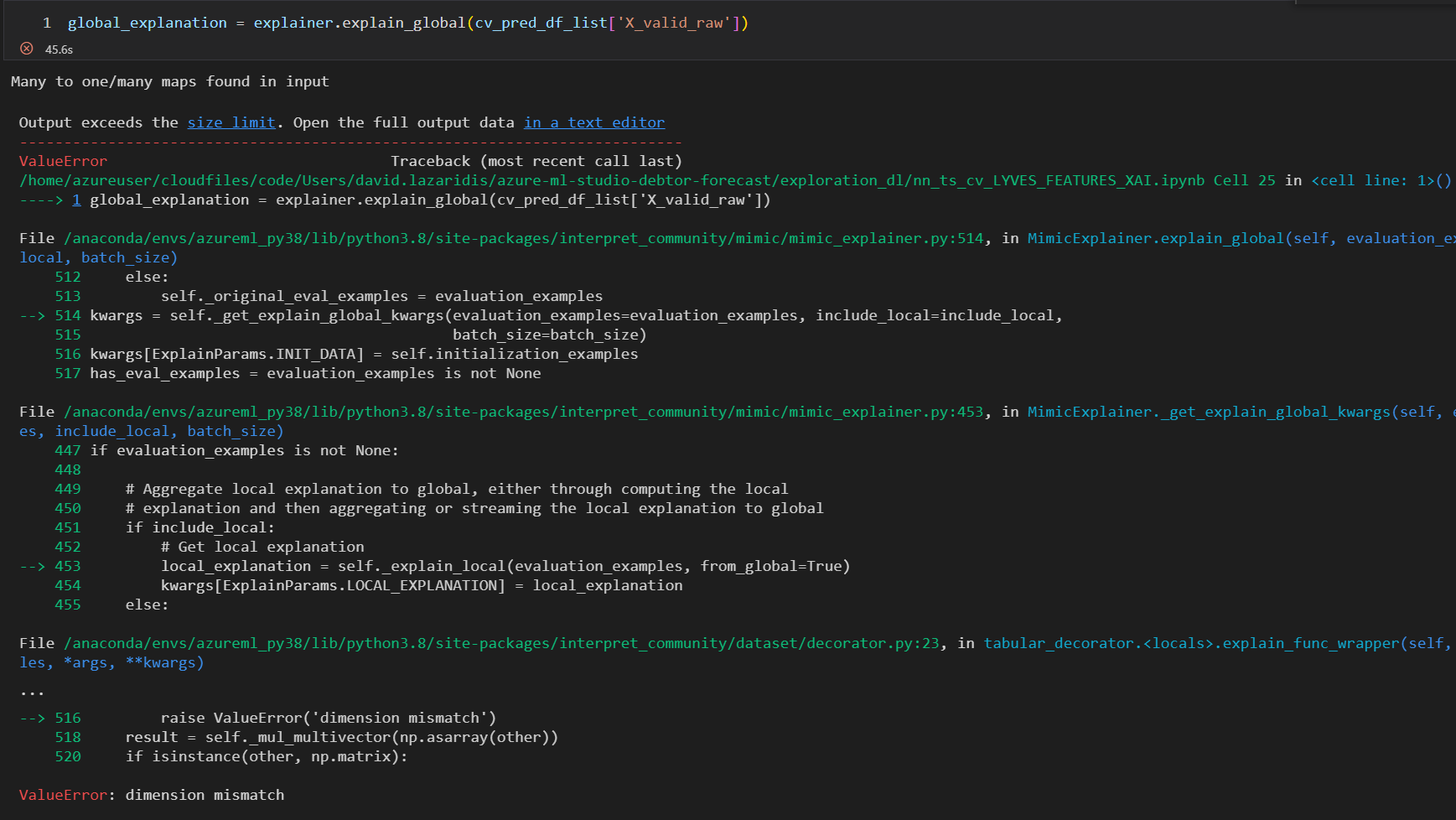
However, if I set a different transformer for each categorical feature, the Explainer works, albeit with a Many to one/many maps found in input warning and produces outputs that don't really make sense (Half the features end up having very, very similar SHAP values).

# Define categorical transformer
categorical_transformer = Pipeline(
steps=[
("cat_impute", SimpleImputer(strategy="constant", fill_value='missing')),
("onehot", OneHotEncoder(drop=None, handle_unknown="infrequent_if_exist", sparse=False, min_frequency=0.01)),
]
)
# Define numeric transformer
numeric_transformer = Pipeline(
steps=[
("imputer", SimpleImputer(strategy="median")),
("scaler", StandardScaler()),
]
)
# Construct list of categorical transformers
categorical_treatments_list = [(feature, categorical_transformer, [feature]) for feature in categorical_features]
# Construct the data preprocessor
data_preprocessor = ColumnTransformer(
transformers=[
("num", numeric_transformer, numeric_features),
*categorical_treatments_list
],
remainder="drop",
)
The documentation suggests that the sklearn
OneHotEncodershould be a viable transformation when using theMimicExplainer, but I'm getting errors if I use it and set themin_frequencyparameter to remove category levels with low counts.If I set up my data preprocessor like this
(where I have ~7 categorical features, each with many levels)
I get the following error

However, if I set a different transformer for each categorical feature, the Explainer works, albeit with a
Many to one/many maps found in inputwarning and produces outputs that don't really make sense (Half the features end up having very, very similar SHAP values).